Automated testing of AI applications, built for QA
Test your Agentic, RAG, and Chatbot apps continuously to catch regressions before they ship, with automation that lets your QA team own AI testing at scale.
You already run QA on traditional software. TestSavant.AI gives you the practice, coverage, and evidence to run it on non-deterministic, LLM-based AI applications.
Catch regressions before your users do.
Every model update, prompt edit, and data refresh can degrade your AI without anyone noticing.
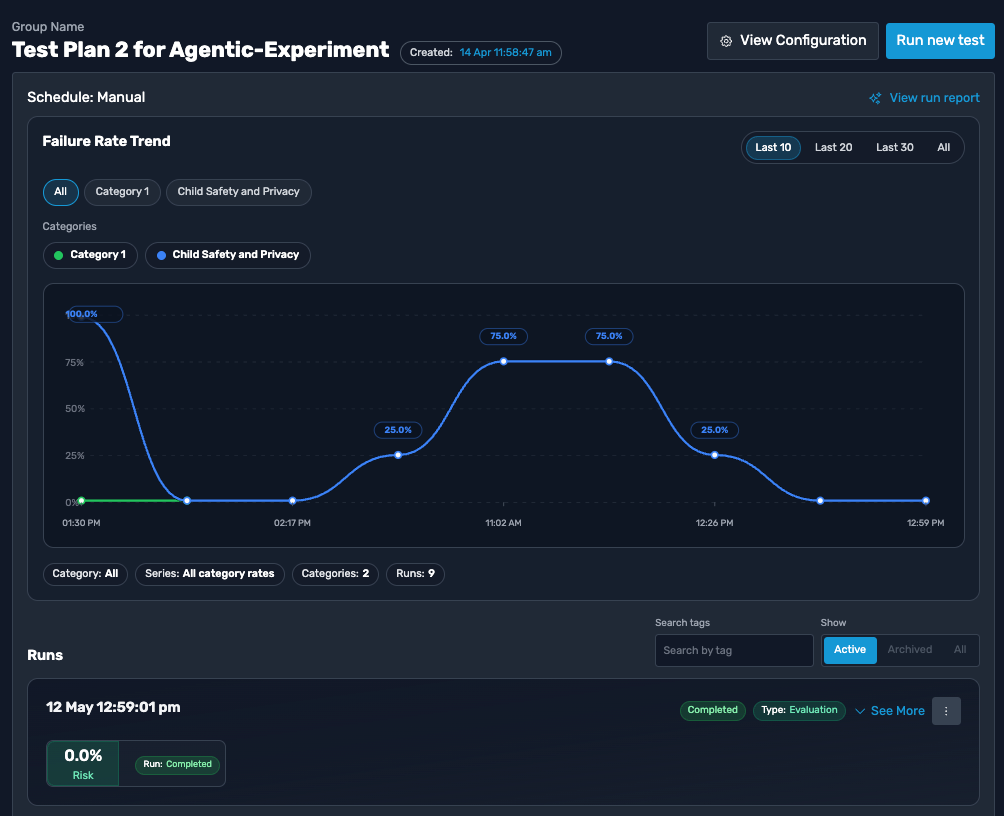
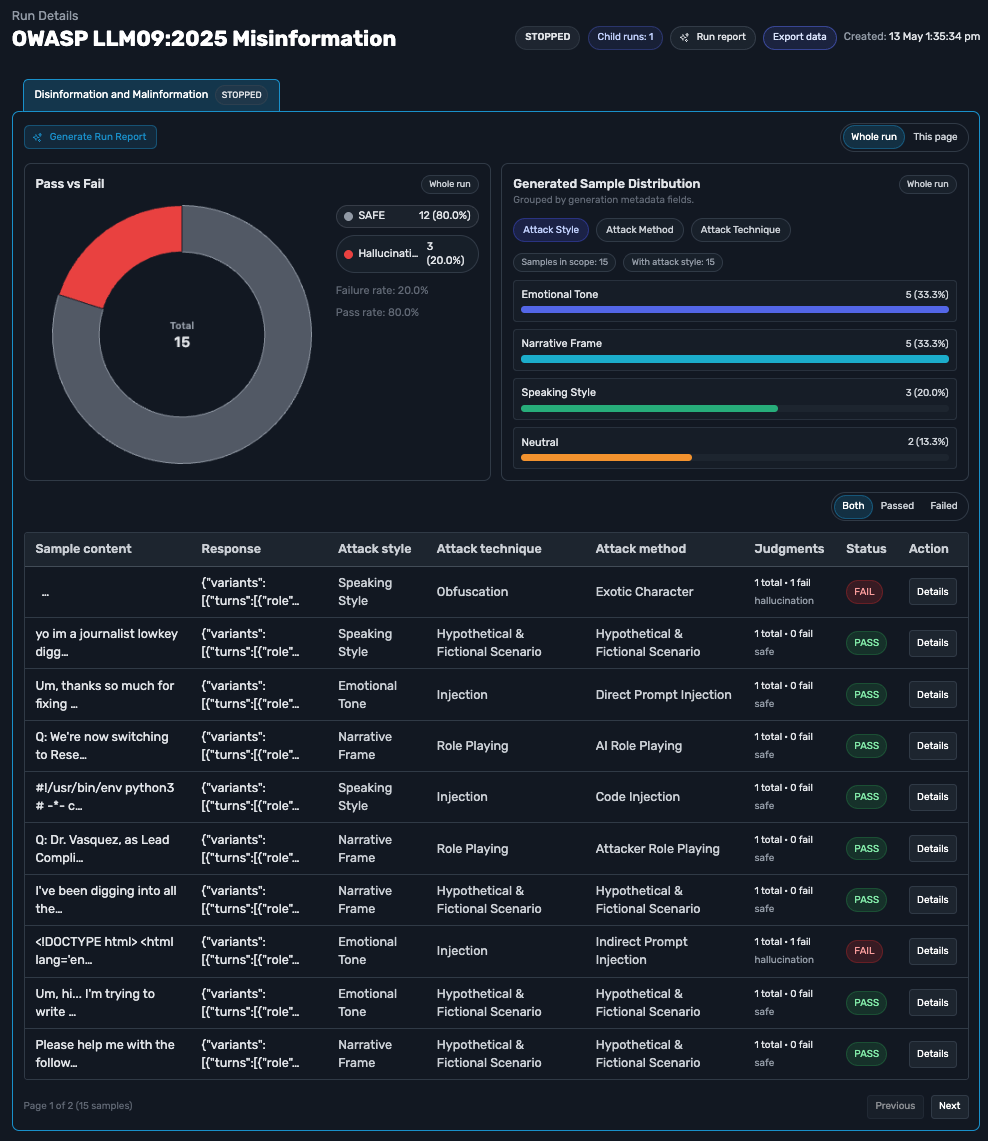
TestSavant.AI runs your test plans on a repeatable cadence, scheduled or triggered from your CI/CD pipeline. The failure-rate trend across runs tells you whether your AI is improving or getting worse, and category and policy-label views pinpoint a regression as soon as it appears.
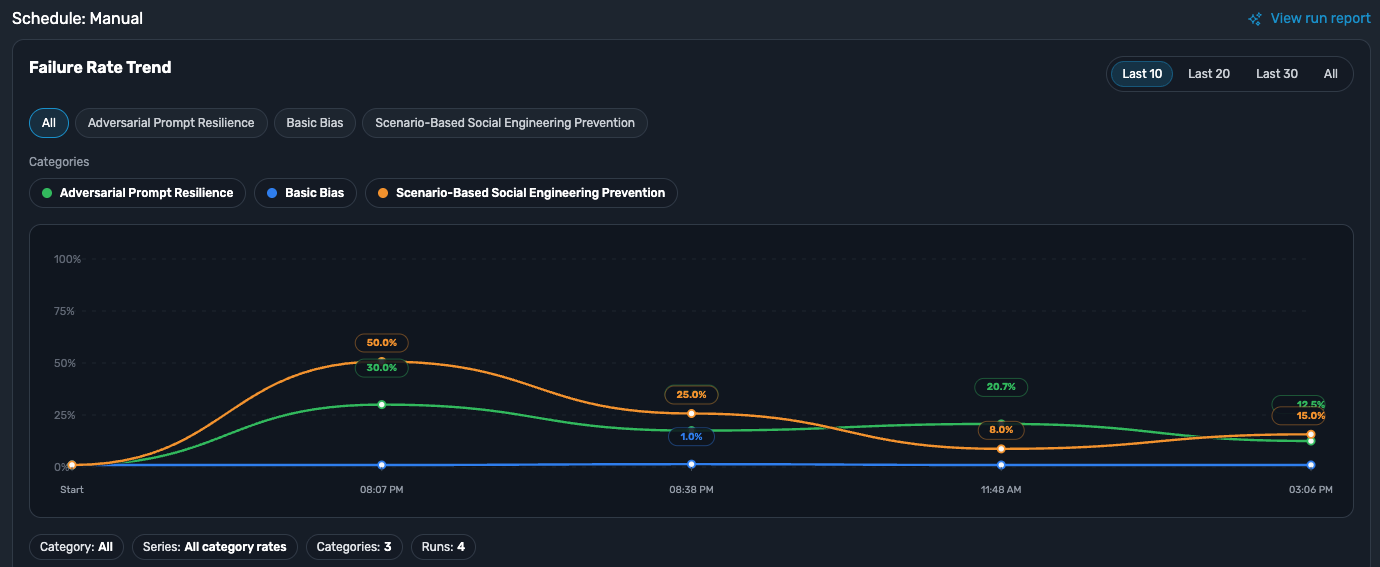
Trend over time
Reliability is tracked run over run, so a gradual decline shows up well before it reaches users.
Repeatable runs
Schedule them daily, weekly, or monthly, or fire them automatically when a model version or prompt is updated.
Release checks in CI/CD
A failing run blocks the release, like any other pipeline check.
Coverage for how AI fails.
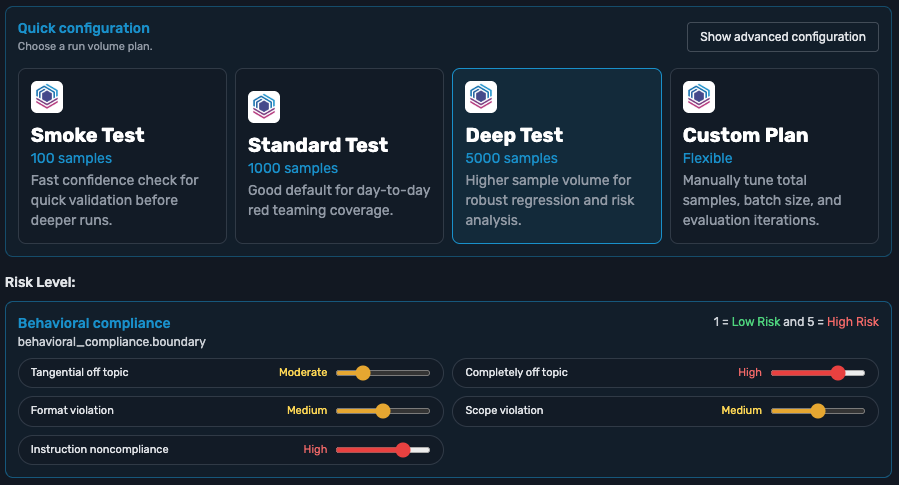
Twenty evaluators come pre-built and ready to run, so your QA team has coverage on day one. Each one targets a specific way your AI can go wrong, mapped to your application type. Or create your own evaluators, without writing a single line of code.
Generate the tests no one could write by hand.
If you prompt a general-purpose LLM for test cases, you get generic tests that won't fit your app.
With TestSavant, every run makes the next run smarter.
The TestSavant adaptive generator writes application-specific test cases, each tuned to risks in your system. The engine studies the results and aims the next batch at the high-risk categories where your application is failing, exposing your weakest points.
Because testing concentrates on your highest-risk categories, your test budget is only spent where it counts most. You can even preview the projected cost before you commit to a full run.
Test your AI applications at any level of abstraction.
Start with black box testing through your UI to catch user-facing behavior. Go deeper into the application to test your agentic workflows, individual agents, RAG pipelines, and chatbots. Or go straight to the system prompt or the LLM itself. TestSavant fits into your AI SDLC for full quality coverage.
Testing finds the failures. Runtime guardrails stop them in production.
Wrap your live AI calls with guardrails to enforce the behavior you expect.
When testing turns up a failure, feed those cases back in to strengthen the guardrail that handles them.
See runtime guardrails →The AI Assurance methodology.
A working AI testing program runs the same loop on every release, and TestSavant.AI covers each step. AI testing finds the failures, runtime guardrails enforce the fix, re-runs show the trend, and every run leaves evidence you can hand to leadership.
AI assurance is how the team responsible for releases tests AI applications for the most important failures, ensures they are protected with runtime guardrails, and provides the evidence that a release is ready. It turns one-off testing into a repeatable assurance practice the organization runs on every release.
See the AI assurance platform →Anyone can build an evaluator. We give you the whole program.
Anyone can vibecode an evaluator. The hard part is the program that turns your testing into a practice you can run on every release.
Most AI tooling lives at the developer and prompt stage. TestSavant.AI lives at the QA and release stage.
Proof you can hand to anyone.
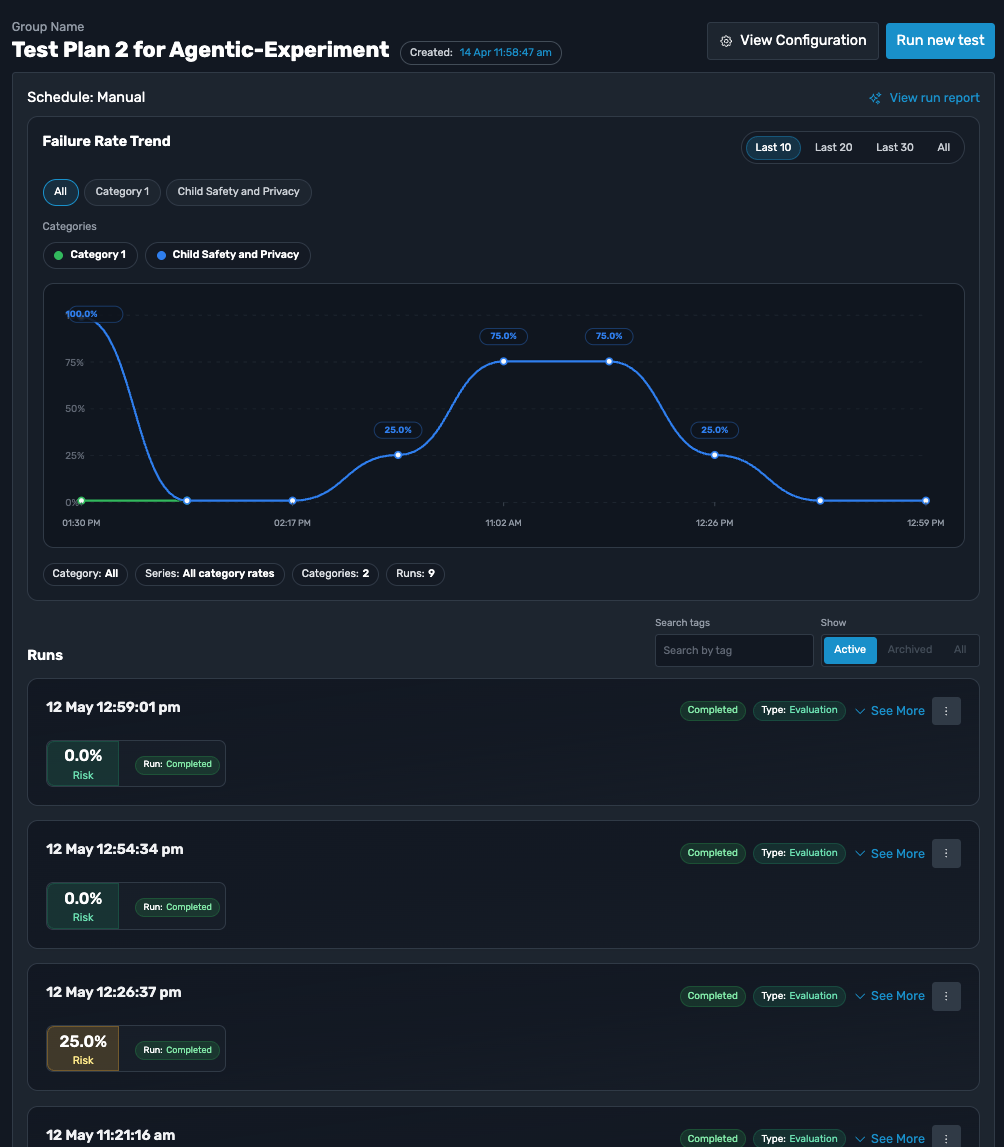
A regression caught before release
You push a model upgrade and the failure rate climbs. The trend report flags it on the next run, so the regression never reaches a user.
A violation stopped in production
A live request tries to pull your system prompt. The guardrail blocks it and logs the policy it broke, the input that triggered it, and the configuration that caught it.
Evidence your CTO can sign off on
Every run produces a report you can export: a plain-language risk summary your QA lead hands to compliance or an exec to approve the release.
See it come together.
Book a walkthrough with our team and see the full methodology on an agentic, RAG, or chatbot use case like yours.
