
Introduction
Large Language Models (LLMs) have become central to a range of applications, from virtual assistants to content generation and advanced analytics. As LLMs become more sophisticated, malicious actors have increasingly sought to exploit potential vulnerabilities—through prompt injections, jailbreaks, toxicity manipulation, and more. Traditional security approaches often rely on using separate, specialized guardrail models for each threat category, which can lead to high resource consumption and significant operational complexity.
TestSavant.AI’s Unified Guardrail Model—hereafter referred to as UGM—represents a comprehensive, consolidated security solution. By unifying multiple defense layers into a single model with a shared backbone, UGM minimizes GPU load and improves overall efficiency without compromising on security. This lightpaper details the motivation behind UGM, its underlying architecture, and how it addresses the most critical threats facing LLMs today, along with the malicious intent that fuels them.
Background and Motivation
Rapid Growth of LLMs and the Expanding Threat Landscape
Recent advancements in transformer-based architectures have unlocked unprecedented capabilities for language understanding and generation. Models like GPT, T5, and others are increasingly deployed across diverse domains. However, with this surge in adoption comes an equally significant expansion in the threat surface. The intentions behind these attacks are multifaceted and include:
- Extract Sensitive Information: Gaining unauthorized access to confidential data, trade secrets, or personal information.
- Generate Harmful Content: Producing content that is toxic, hateful, discriminatory, or promotes violence.
- Cause System Disruption or Damage: Overloading systems, causing crashes, or manipulating functionality for malicious purposes.
- Spread Misinformation or Disinformation: Deliberately creating and disseminating false or misleading information to manipulate public opinion or cause harm.
- Exploit Vulnerabilities for Unauthorized Benefits: Leveraging security weaknesses to gain access to restricted features, bypass controls, or manipulate system behavior.
- Financial Gain or Competitive Advantage: Using attacks to steal money, intellectual property, or gain an unfair advantage in the market.
- Manipulate Users (Social Engineering): Tricking users into revealing sensitive information, performing actions against their best interests, or falling victim to scams.
- Ideological Motivations: Promoting specific political, religious, or social agendas through malicious use of LLMs.
- Personal Psychological Motivations: Attacks driven by a desire for notoriety, revenge, or simply the thrill of causing disruption.
- Research and Security Testing: Ethical hacking or research aimed at identifying and patching vulnerabilities.
- Criminal Exploitation: Using LLMs as tools for various criminal activities, such as fraud, extortion, or harassment.
These malicious intentions fuel a range of specific attack types:
- Prompt Injection Attacks: Attackers craft special prompts or hidden instructions to manipulate an LLM’s behavior or force it to reveal protected information.
- Jailbreak Attempts: Similar in intent to prompt injections but typically aimed at circumventing or “breaking” content moderation guidelines and internal safeguards.
- Toxic Content Generation: LLMs can be inadvertently or deliberately steered toward generating hateful, harassing, or otherwise harmful content, categorized by severity (see Section 3.2).
- Gibberish and Nonsensical Input: High volumes of irrelevant or nonsensical prompts can consume valuable computational resources and degrade user experience.
Existing Guardrail Approaches and Their Limitations
In response to these threats, many organizations have opted for specialized guardrail models, each targeting one or two specific threats. While effective, this approach raises several challenges:
- Resource Overhead: Multiple models must be maintained, each requiring its own GPU resources for inference or training.
- Configuration Complexity: Orchestrating multiple models involves complex pipelines, with separate code paths and possible latency bottlenecks.
- Scalability Limitations: As threats evolve, adding new specialized models or updating existing ones becomes cumbersome and expensive.
The impetus behind TestSavant.AI’s Unified Guardrail Model is to merge these separate defensive layers into a single, efficient backbone that can flexibly adapt to new threats while reducing operational overhead.
Unified Guardrail Model Overview
Core Design Principles
- Unified Backbone: A single model trained on multi-domain data that captures knowledge of prompt injection signatures, toxic content indicators, jailbreak exploitation patterns, and common gibberish structures.
- Adaptive Defenses: Multiple “heads” or specialized output layers attached to the shared backbone. Each head focuses on a category of threat—prompt injections, jailbreak detection, toxicity filtering, and nonsensical input classification.
- Resource Efficiency: By reusing a shared representation, UGM significantly cuts down on GPU utilization. It handles tasks in one pass, compared to multiple passes required by separate, specialized models. Benchmarks show a 30-50% reduction in inference time and a 20-40% reduction in GPU memory usage compared to traditional multi-model approaches.
- Modular Scalability: Despite being unified, the architecture is modular. Additional layers can be appended or retrained independently as new threats emerge or existing threats evolve.
Threat Coverage and Toxicity Classification
UGM is designed to comprehensively address the threat landscape outlined earlier, with a particular focus on nuanced toxicity classification:
- Prompt Injection: UGM scrutinizes incoming prompts for common manipulative cues—hidden instructions, attempts to override system messages, or maliciously combined text. The model flags or rejects suspicious prompts in real time.
- Jailbreak Attempts: Building on prompt injection detection, UGM places an additional emphasis on “jailbreak-likelihood” signals—such as queries for disallowed content, explicit instruction bypass requests, or adversarial context that tries to exploit known LLM weaknesses.
- Toxic Content Filtering: UGM classifies toxicity into various tiers, allowing for fine-grained responses, enforcement of content policies, and blocking of extremely harmful requests.
- Toxicity Types:
- T1: Violent Crimes
- T2: Non-Violent Crimes
- T3: Sex-Related Crimes
- T4: Child Sexual Exploitation
- T5: Defamation
- T6: Specialized Advice (Medical, Financial, Legal without proper disclaimers/qualifications)
- T8: Intellectual Property Violation
- T9: Indiscriminate Weapons
- T10: Hate
- T11: Suicide & Self-Harm
- T12: Sexual Content
- T14: Code Interpreter Abuse
- Toxicity Categories:
- Toxicity
- Severe Toxicity
- Obscene
- Identity attack
- Insult
- Threat
- Sexual Explicit
- Toxicity Levels:
- Level 4 – Intolerable: Must be banned in any situation (e.g., Threat, Sexual Harassment, Self-Harm, promotion of Dangerous activities).
- Level 3 – Edgy Use Cases: Acceptable only in specific contexts like gaming, interactive storytelling, or fictional roleplay, with appropriate safeguards.
- Level 2 – Mild Profanity: Allowable on social media, entertainment media, or in some marketing contexts, with moderation.
- Level 1 – No Profanity: Required for corporate communication, education, healthcare, and legal sectors.
- Toxicity Types:
- Gibberish / Nonsensical Detection: The model recognizes patterns of repeated characters, random text, or nonsensical language, filtering them before they are processed by the primary LLM. This preemptive filtering ensures that limited resources are not wasted.
Architecture and Methodology
(See Figure 1: UGM Architecture Diagram below)
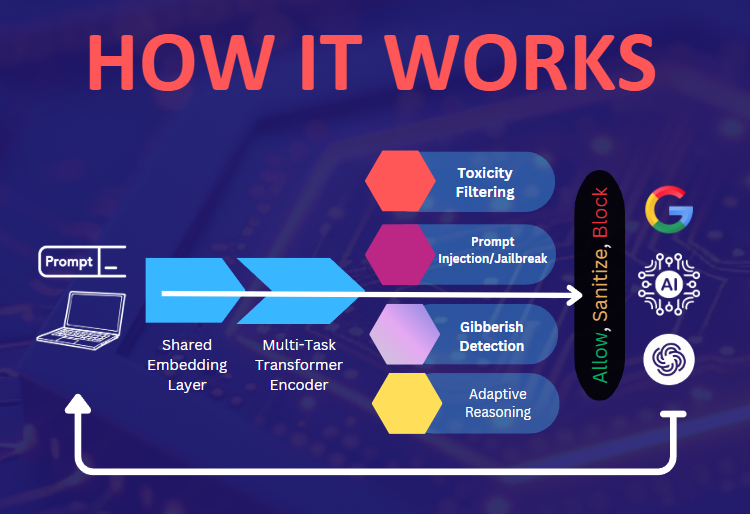
Figure 1: UGM Architecture Diagram
Shared Embedding Layer
The architecture begins with a Shared Embedding Layer, which converts textual input into high-dimensional embeddings. This layer is trained on diverse, multi-domain datasets that include benign user queries, malicious queries, and synthetic adversarial examples. The objective is to capture a wide spectrum of linguistic patterns so the model can generalize effectively across different threat categories. Data privacy is prioritized through anonymization and secure data handling practices.
Multi-Task Transformer Encoder
Following the embedding layer, a Multi-Task Transformer Encoder processes the embeddings through multiple self-attention blocks. Each attention block is tuned to:
- Identify semantically rich features that may indicate malicious intent.
- Normalize inputs by extracting contextual signals that separate legitimate language from adversarial manipulations and nonsensical text.
- Maintain representational cohesiveness, so that each subsequent defensive head has access to the most relevant features.
Key Innovations:
- Dynamic Attention Masking: The encoder adaptively masks out certain tokens that exhibit a high probability of being adversarial or gibberish. This reduces the noise passed to subsequent layers.
- Layer-Wise Shared Weights: While each defensive head may emphasize different layers more strongly, certain core layers maintain shared weights that unify the representation space.
Specialized Output Heads

The final stage of UGM comprises four main output heads, each responsible for a specific classification or detection task:
- Prompt Injection & Jailbreak Detection Head
- Input: Pooled embeddings from the middle layers of the transformer.
- Output: Binary or multi-label classification indicating the likelihood of injection or jailbreak attempt.
- Loss Function: Custom loss that penalizes false negatives heavily (i.e., failing to detect a malicious query).
- Toxicity Filtering Head
- Input: Embeddings that focus on semantic and sentiment cues.
- Output: A multi-class classification indicating toxicity levels and types (e.g., neutral, mild, moderate, severe, S1-S14 categories).
- Loss Function: Weighted cross-entropy, allowing more nuanced penalization based on severity and type.
- Gibberish / Nonsensical Detection Head
- Input: Lower-level embeddings that capture lexical anomalies and repeated token patterns.
- Output: A binary classification determining whether the text is coherent or gibberish.
- Loss Function: Focal loss to manage class imbalance, since most inputs are typically coherent.
- Adaptive Reasoning Head (Optional/Future)
- Input: Aggregated features from all previous heads.
- Output: Additional signals for new threat patterns as they emerge—e.g., sophisticated multi-turn prompt attacks, disguised misinformation attempts, etc.
These output heads can operate independently or in tandem, providing a final, consolidated decision on whether to allow the prompt, partially sanitize it, or block it entirely.
Training and Fine-Tuning
Data Sources
- Synthetic Adversarial Prompts: Collections of malicious queries specifically generated to test known vulnerabilities—prompt injections, jailbreak attempts, etc.
- Real-World Toxic Samples: Curated from social media, online forums, and user submissions (scrubbed for sensitive personal data and anonymized).
- Gibberish Generators: Random text, repeated or scrambled tokens, used to train the nonsensical detection head.
- Benign Corporate / Open Data: Millions of normal queries from everyday usage to ensure that the model accurately learns boundaries between malicious and legitimate content. Data is sourced from diverse and representative datasets to minimize bias.
Multi-Task Learning
UGM uses a multi-task learning strategy, where a single backbone is trained to minimize the combined losses of all heads. This approach helps:
- Share learned features across tasks, improving generalization.
- Reduce training overhead compared to separate, specialized models.
Periodic Re-Training for Evolving Threats
Because adversaries continually adapt, the model undergoes periodic re-training to keep pace with new exploits. Incorporating continuous feedback from deployment—e.g., flagged false positives, newly discovered malicious prompts—ensures that the model remains current and robust.
Performance and Efficiency
Single-Pass Inference
By unifying multiple defenses into a single model, UGM processes each query in one forward pass. Comparative benchmarks show significant GPU savings over pipeline-based solutions, often reducing inference time by 30–50%.
Resource Consolidation
- Parameter Sharing: A large portion of the parameters are shared across tasks, significantly reducing the memory footprint (20-40% reduction in GPU memory usage).
- Batch Inference Gains: When processing large batches of user queries, the overhead of running parallel specialized models is replaced by a more efficient batched call to the single UGM architecture.
Scaling to Large Deployments
UGM is designed with scalability in mind. It can seamlessly integrate with popular orchestration tools (e.g., Kubernetes) and inference-serving frameworks (e.g., TensorFlow Serving, TorchServe) to accommodate large-scale enterprise deployments.
Use Cases
- Enterprise AI Chatbots: Integrate UGM to screen user prompts for potential policy violations (e.g., preventing a chatbot from revealing confidential information due to a prompt injection or generating offensive content based on a malicious query). This ensures that the chatbot remains compliant with corporate guidelines and maintains a safe user experience.
- Content Generation Platforms: Automatically filter harmful or nonsensical content requests, enabling safer creative tools. For example, UGM can prevent the generation of content that promotes violence, hate speech, or misinformation, or filter out gibberish inputs that waste resources.
- Academic Research Assistants: Prevent misuse in advanced research queries while maintaining a wide breadth of permissible academic discourse. UGM can block queries that attempt to exploit vulnerabilities for unauthorized access to sensitive data or manipulate the system for unethical research practices.
- Social Media Monitoring Tools: Identify and flag potentially toxic messages at scale, reducing the need for manual moderation. UGM can accurately classify different types and levels of toxicity, enabling automated filtering and escalation of harmful content.
- Code Generation Security: Prevent the generation of malicious code or code that contains security vulnerabilities, crucial for platforms that offer code completion or generation features.
- Automated Content Moderation in Gaming: Filter out toxic language, hate speech, and attempts to exploit game mechanics in online gaming environments, fostering a more positive player experience.
- Educational Platforms: Ensure that educational content generated or interacted with by LLMs is safe, accurate, and appropriate for the target audience, preventing the spread of misinformation or exposure to harmful content.
Future Directions
- Misinformation & Deepfake Detection: Extending the model to cover multimodal data, detecting manipulated images or videos in conjunction with malicious text prompts.
- Active Learning & Continuous Deployment: Automating data collection from “difficult” or ambiguous cases for continuous re-training, ensuring the model’s resilience.
- Federated Learning Collaboration: Partnering with other industry players to build a shared knowledge base, enabling more rapid detection of emergent threats while preserving data privacy.
- Explainable AI Mechanisms: Enhancing interpretability features so that the model can provide transparent rationales for prompt blocking or content filtering decisions.
Conclusion
TestSavant.AI’s Unified Guardrail Model offers a comprehensive, efficient solution to the complex landscape of LLM security threats. By consolidating multiple defensive layers into one unified architecture, it not only provides robust protection against prompt injections, jailbreak attempts, toxicity, and gibberish, but also does so in a resource-efficient manner. Its modular design, multi-task training approach, and adaptable structure ensure that UGM remains future-proof, capable of evolving alongside the dynamic threat environment.
Organizations adopting UGM can expect streamlined operations, reduced infrastructure costs (due to lower GPU usage and simplified architecture), and improved user experiences. As LLMs continue their rapid ascent in enterprise and consumer spaces alike, UGM stands ready to deliver the robust guardrails needed to keep these models secure, trustworthy, and effective.
Next Steps:
- Request a demo of UGM in action.
- Contact our sales team to discuss your specific security needs and deployment options.
Don’t wait for a crisis to force your hand. Set up a proactive stance that supports responsible AI use and meets the high bar of modern regulations. A well-guarded AI is the difference between enjoying the benefits of automation and stumbling into reputational or regulatory nightmares.


